VIRAL: Vision-grounded Integration for Reward design And Learning
▶️ Watch the Demo Video

Click the image above to watch our demo video on YouTube.
🚀 Overview
VIRAL (Vision-grounded Integration for Reward design And Learning) provides a new approach to reward engineering, inspired by DREFUN-V. This project investigates how VideoLLMs (Video Large Language Models) can be used to better align reward functions with task objectives in RL settings.
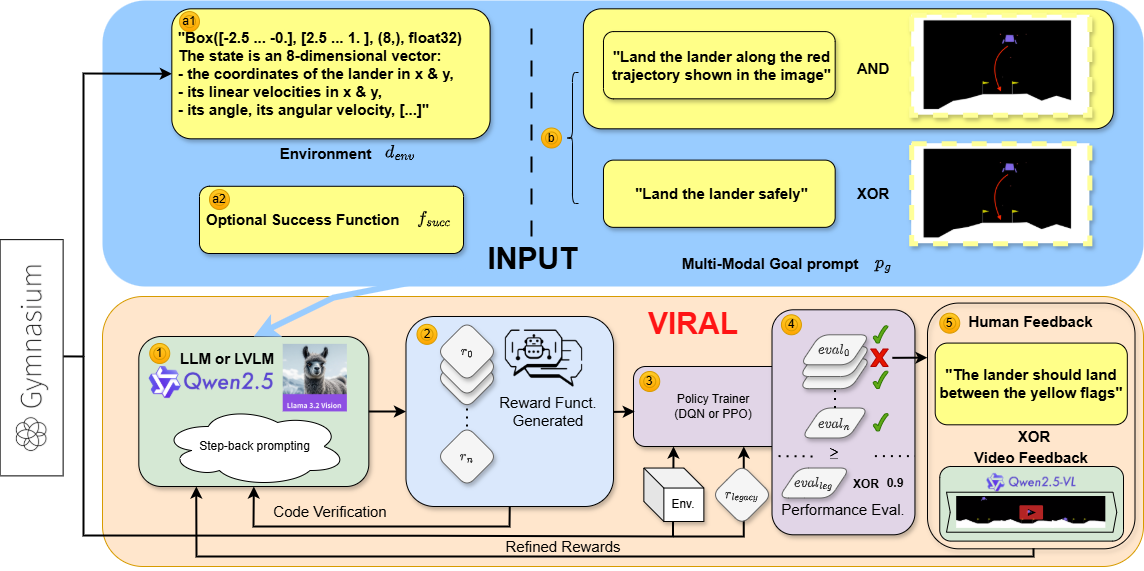
For more details, see our paper (PDF) or ArXiv preprint.
📁 Repository Contents
- Source code: Core implementation of the VIRAL framework
- Project website and documentation: Documentation & Website
- Experimental results: Results repository
- Paper: Read the full paper (PDF) or on ArXiv
📖 Get Started
For installation instructions, usage examples, and detailed documentation, please visit our project website.
📚 Learn More
- Course inspiration:
Theory and Practical Applications of Large Language Models – by Bruno YUN
🙏 Acknowledgements
This project was developed as part of the course on Large Language Models at UCBL1, under the guidance of Bruno YUN.
Questions or suggestions?
Feel free to open an issue.